

Este robot de DeepMind sólo ha recibido una tarea, ha aprendido por sí mismo a moverse y completarla

DeepMind, la filial de Alphabet dedicada al desarrollo de la inteligencia artificial y el aprendizaje automático, ha conseguido un nuevo logro. Dejando de lado juegos de mesa como el Go, le han encomendado a un brazo robótico la tarea de guardar todos los objetos de una mesa en una caja. Con esta simple tarea en mente, el brazo robótico ha tenido que ingeniárselas primero para aprender a moverse usando sus sensores y habilidades, luego para guardar los objetos y cumplir la tarea.
A DeepMind la conocemos principalmente por sus progresos con AlphaGo, la inteligencia artificial que crearon para ser la mejor jugadora del mundo en el Go. Una evolución de esta inteligencia, AlphaGo Zero, aprendió a jugar por si sola al Go y batió 100 veces a 0 a su antigua versión. Básicamente se entrenó por si misma, sin basarse en la experiencia recopilada de partidas reales. Con SAC-X, el nuevo proyecto de DeepMind, van un paso más allá. A la inteligencia artificial ni siquiera se le dan las reglas o su manera de funcionar, sólo una tarea que cumplir. Y esto aumenta la dificultad de manera considerable.
var _giphy = _giphy || [];
_giphy.push({id: «8mkylYpdmC8FrDKraT», clickthrough_url: «//giphy.com/media/8mkylYpdmC8FrDKraT/giphy.gif»});
var g = document.createElement(«script»);
g.async = true;
g.src = («https:» == document.location.protocol ? «https://» : «http://») + «giphy.com/static/js/widgets/embed.js»;var s = document.getElementsByTagName(«script»)[0]; s.parentNode.insertBefore(g, s);
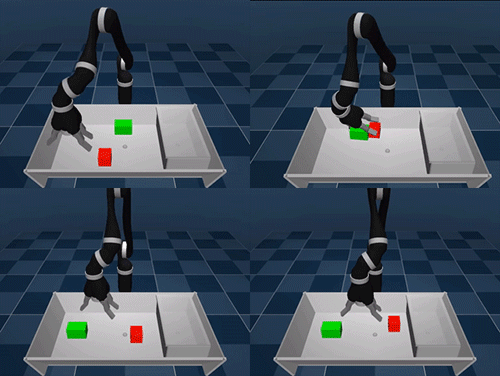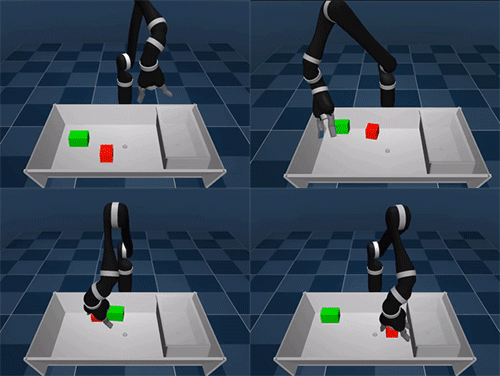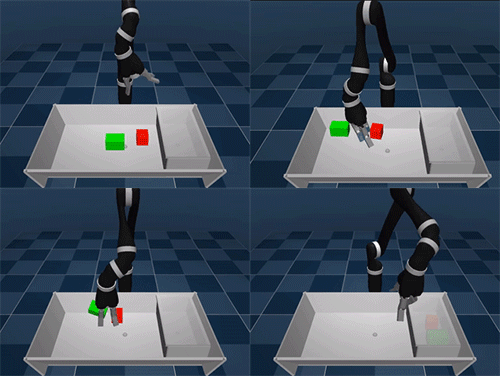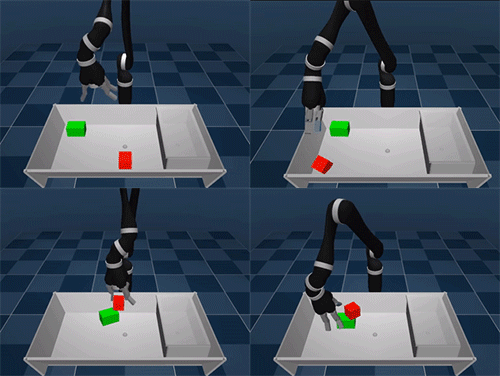
Primero aprende a moverte, luego soluciona el problema
El experimento se ha llevado a cabo en un espacio virtual donde un brazo robótico tenía a su alcance una mesa con varios cubos y una caja donde colocarlos. Para completar la tarea primero debe conocer los recursos de los que dispone, que en este caso son ese brazo robótico con todos los sensores apagados y por descubrir. Al comenzar a mover el brazo encuentra los sensores que le permiten detectar la proximidad o medir su fuerza por ejemplo, así practica hasta conseguir controlar el brazo robótico coordinando todas sus articulaciones.
El siguiente paso es interactuar con los dos cubos que se encuentran en la mesa: los toca, los empuja, los coge y levanta… Y por último, aprende a levantar la tapa de la caja y a guardar los dos cubos dentro. El proceso es de lo más curioso, de un primer vistazo nos puede parecer un robot algo inepto (más si lo comparamos con el perro-robot de Boston Dynamics), pero teniendo en cuenta que ha aprendido desde cero… recuerda mas bien a un bebe que está descubrido a coger objetos y a caminar.
La motivación del brazo robótico es conseguir una recompensa, un punto virtual. Por cumplir acciones pequeñas recibe pequeñas puntuaciones, por guardar los objetos en la caja recibe la puntuación máxima. De este modo, el robot descubre que si aprende a coger un objeto se le recompensa por ello, también por apilar los cubos. Pero como no hay recompensa por sacar fuera de la mesa un cubo, entiende que ese no es el camino a seguir en su aprendizaje. En otras palabras, traza su propio plan de aprendizaje para adaptarse al contexto en el que se encuentra, aprende a aprender.
¿Cuál es el objetivo de todo esto? Conseguir que una inteligencia artificial sea capaz de aprender desde cero adaptándose al entorno en el que se encuentra y aprovechando los recursos de los que dispone. Las decisiones que debe tomar un brazo robótico son mucho mayores que las que se deben tomar en una partida del Go. SAC-X es un sistema de inteligencia artificial que esperan aplicar en muchos otros ámbitos, se especifica un objetivo general y se le deja aprender.
Más información | DeepMind
En Xataka | ‘AlphaGo’ es el documental de Netflix que mejor explica lo que supuso la victoria de la IA de Google al campeón de Go
También te recomendamos
Google ha enfrentado dos sistemas de inteligencia artificial: ¿lucharán o trabajarán juntos?
Cómo organizar mejor los servicios en la Nube que tenemos a punto de reventar
–
La noticia
Este robot de DeepMind sólo ha recibido una tarea, ha aprendido por sí mismo a moverse y completarla
fue publicada originalmente en
Xataka
por
Cristian Rus
.

























